

Cuando los humanos navegamos por internet recordamos más facilmente una dirección web (www.MiNombreDeDominio.es) , que una cadena de números separada por puntos (IPv4: 193.146.1.101) o números hexadecimales (IPv6: 2001:720:438:402:0:0:0:90). De este modo básico funciona el sistema de nombres de dominio (DNS) ; nuestra propia «agenda de teléfono» distribuida y jerárquica en todo el mundo que traduce un nombre más inteligible en direcciones IP asignadas a un ordenador, del mismo modo que cuando llamamos a un contacto «Javier» nuestro teléfono marca su número.
Continuando con esta analogía, en 1953 si necesitabamos buscar a que persona correspondía un número de teléfono de 10 dígitos, un ordenador podría simplemente realizar lecturas hasta encontrar la coincidencia. Si la lista es de millones de números nos podría llevar su tiempo dependiendo de la posición en la que se encontrara… por suerte Hans Peter Luhn, entre todas sus patentes e inventos, ideó para IBM un sistema para transformar un elemento complejo en otro más sencillo.
Por ejemplo, el teléfono 948 012 012, agrupado en pares 09 48 01 20 12, sumados entre si 9 12 1 2 3, descartando más de dos dígitos: 92123 reducimos la complejidad y obtenemos para unos datos de entrada un resultado único por el que indexarlo. Acaba de aparecer lo que hoy podemos conocer como función Hash, cuya traducción del inglés sería picar y mezclar, picadillo.
Lo mismo sucedía con las búsquedas de nombres de dominios, hasta 1983 con un pequeño fichero de texto (hosts) se contenían todas las relaciones entre estos nombres y su IP, lo que no fue predecible en aquel momento sería la expansión y uso posterior que dejarían las 4.294.967.296 posibles direcciones agotadas. Por lo que hubo que distribuir en miles de servidores DNS de manera jeraquica. Como curiosidad, para llegar a esta versión 4 que seguimos utilizando a día de hoy, si existieron versiones previas TCP v1, TCP v2, TCP v3 / IP v3 incluso IPv5 que no trascendió más allá del ámbito experimental.
Llegamos a 1993 con la proliferación de servicios de email, aparece el denominado «algoritmo de prueba de trabajo» (PoW: Proof-Of-Work system) como posible mecanismo para intentar dificultar el correo no deseado (SPAM) o los ataques de denegación de servicio distribuidos (DDoS). Para ello se requiere realizar algún tipo de trabajo con cierto coste, moderadamente díficil pero factible de realizar por quien envia la petición (cliente) y muy fácil de verificar por quien la recibe (servidor), totalmente asimétrico. Por ejemplo, podría realizar cálculos matemáticos (cálculo de raíces cuadradas, buscar colisión de hash parcial…) añadiendo el resultado en la cabecera del email (Hashcash). Si alguien ha perdido tiempo y esfuerzo en hacer esto, probablemente no sea SPAM… o por lo menos esa era la idea inicial.
En 1996 surge otra tecnología denominada red entre iguales (red de pares, peer-to-peer, P2P) donde todos los nodos que la componen actuan como iguales entre sí, obtienen datos y sirven datos entre ellos (cliente-servidor). Basado en este concepto en 1999 se funda Napster y años posteriores seguirán apareciendo otras aplicaciones y redes que lo utilizan: eMule, BitTorrent, Kad, eDonkey, Gnutella, Ares…
Si bien este tipo de redes se ha relacionado con contenido al margen de la legalidad en muchas ocasiones, tambíen se utiliza para llamadas de VozIP en Skype o la distribución de las actualizaciones de Windows 10 por ejemplo.
Vamos sumando conceptos y tecnologías, en 2008 apareció la «cadena de bloque» (Blockchain) como un nuevo tipo de almacenamiento de datos distribuido. Los bloque de datos se encadenan entre sí, conforme se añaden nuevos datos se integran en un bloque nuevo, cuando se llena se encadena con el anterior en orden cronológico. Todos los bloques contiene su código propio hash, el hash del bloque anterior y una marca de tiempo. Se puede almacenar cualquier tipo de dato, pero el uso inicial más común ha sido para almacenar un libro mayor de transacciones de donde nace la moneda virtual (Bitcoin)
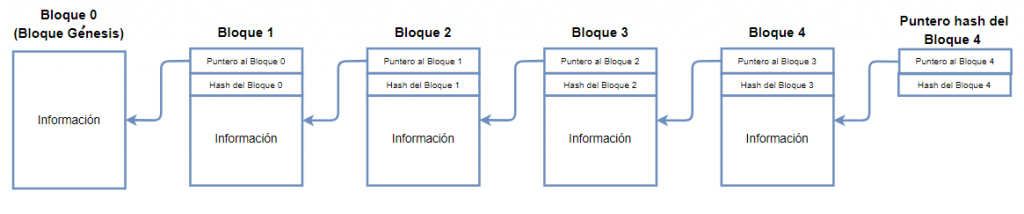
Al registrarse una transacción/movimiento, la red blockchain debe verificar su autenticidad, donde miles de ordenadores se apresuran a confirmar que los detalles de la compra son correctos (PoW, aquí entra en juego la denominada minería), si todo es correcto se añade el nuevo bloque, se recompensa a quien obtuvo antes la comprobación y se comparte al resto de nodos.
Si hasta este momento era posible guardar información en grandes bases de datos, incluso podían estar distribuidas en miles de servidores, siempre estaban bajo el control de una misma empresa u organismo. La descentralización de la información, en el casto de esta criptomoneda, se realiza distribuyendo en miles de nodos/ordenadores en ubicaciones geográficas dispares; esto no implica que la tecnología blockchain no pueda hacerse en redes centralizadas o de la misma propiedad pero de este modo implica una transparencia inimaginable hasta la fecha.
Si un usuario intenta manipular la información contenida en uno de los bloques, el resto de nodos que apuntan a la misma información marcarían la discrepancia (hash modificado) con el resto, para aceptar el cambio la mayoría de los nodos (el 51%) necesitarían aceptar y procesar los cambios. Democracia digital podríamos llamarlo.
Dentro de esta transparencia puede verse incluso las transacciones que ocurren en tiempo real, por tanto podrían rastrearse los movimientos de Bitcoin pero no podríamos identificar, dado que son confidenciales, quien está detrás de la cuenta final.
En este caso la suma de tecnologías crea una nueva: Hash + PoW + IP + P2P + Blockchain = Bitcoin
De este modo, podemos registrar y distribuir información no editable una vez emitida, guardando un orden cronológico de cambios hasta su última versión; puede aplicarse a sistemas de votaciones, trazabilidad alimentaria, cadenas de suministros, registros médicos, contratos, escrituras de viviendas, registros públicos… o ¿por qué no? también para los servicios de resolución de nombres (DNS) con los que empezamos.








